Amazon OpenSearch Service just recently revealed Multi-AZ with Standby, a brand-new implementation choice for handled clusters that makes it possible for 99.99% schedule and constant efficiency for business-critical work. With Multi-AZ with Standby, clusters are resistant to facilities failures like hardware or networking failure. This choice offers enhanced dependability and the included advantage of streamlining cluster setup and management by imposing finest practices and lowering intricacy.
In this post, we share how Multi-AZ with Standby works under the hood to attain high resiliency and constant efficiency to satisfy the 4 nines.
Background
Among the concepts in developing extremely readily available systems is that they require to be all set for disabilities prior to they occur. OpenSearch is a dispersed system, which works on a cluster of circumstances that have various functions. In OpenSearch Service, you can release information nodes to save your information and react to indexing and search demands, you can likewise release devoted cluster supervisor nodes to handle and manage the cluster. To offer high schedule, one typical technique for the cloud is to release facilities throughout several AWS Schedule Zones. Even in the uncommon case that a complete zone ends up being not available, the readily available zones continue to serve traffic with reproductions.
When you utilize OpenSearch Service, you develop indexes to hold your information and define partitioning and duplication for those indexes. Each index is consisted of a set of main fragments and absolutely no to lots of reproductions of those fragments. When you in addition utilize the Multi-AZ function, OpenSearch Service makes sure that main fragments and reproduction fragments are dispersed so that they remain in various Schedule Zones.
When there is a disability in a Schedule Zone, the service would scale up in other Schedule Zones and rearrange fragments to expand the load equally. This technique was reactive at finest. In addition, fragment redistribution throughout failure occasions triggers increased resource usage, causing increased latencies and overloaded nodes, even more affecting schedule and efficiently beating the function of fault-tolerant, multi-AZ clusters. A more efficient, statically steady cluster setup needs provisioning facilities to the point where it can continue running properly without needing to launch any brand-new capability or rearrange any fragments even if a Schedule Zone ends up being impaired.
Creating for high schedule
OpenSearch Service handles 10s of countless OpenSearch clusters. We have actually gotten insights into which cluster setups like hardware (information or cluster-manager circumstances types) or storage (EBS volume types), fragment sizes, and so on are more resistant to failures and can satisfy the needs of typical client work A few of these setups have actually been consisted of in Multi-AZ with Standby to streamline setting up the clusters. Nevertheless, this alone is insufficient. A crucial active ingredient in accomplishing high schedule is preserving information redundancy.
When you set up a single reproduction (2 copies) for your indexes, the cluster can endure the loss of one fragment (main or reproduction) and still recuperate by copying the staying fragment. A two-replica (3 copies) setup can endure failure of 2 copies. When it comes to a single reproduction with 2 copies, you can still sustain information loss. For instance, you might lose information if there is a disastrous failure in one Schedule Zone for an extended period, and at the exact same time, a node in a 2nd zone stops working. To make sure information redundancy at all times, the cluster imposes a minimum of 2 reproductions (3 copies) throughout all its indexes. The following diagram shows this architecture.

The Multi-AZ with Standby function releases facilities in 3 Schedule Zones, while keeping 2 zones as active and one zone as standby. The standby zone provides constant efficiency even throughout zonal failures by guaranteeing exact same capability at all times and by utilizing a statically steady style with no capability provisioning or information motions throughout failure. Throughout regular operations, the active zone serves planner traffic for read and compose demands and fragment inquiry traffic, and just duplication traffic goes to the standby zone. OpenSearch utilizes concurrent duplication procedure for compose demands, which by style has absolutely no duplication lag, allowing the service to instantly promote a standby zone to active in case of any failure in an active zone. This occasion is described as a zonal failover The formerly active zone is benched to the standby mode and healing operations to bring the state back to healthy start.
Why zonal failover is important however tough to do best
Several nodes in a Schedule Zone can stop working due to a variety of factors, like hardware failures, facilities failures like fiber cuts, power or thermal concerns, or inter-zone or intra-zone networking issues. Check out demands can be served by any of the active zones, whereas compose demands require to be synchronously reproduced to all copies throughout several Schedule Zones. OpenSearch Service manages 2 modes of failovers: checked out failovers and the compose failovers.
The mostly objectives of read failovers are high schedule and constant efficiency. This needs the system to continuously keep track of for faults and move traffic far from the unhealthy nodes in the affected zone. The system looks after managing the failovers with dignity, permitting all in-flight demands to end up while all at once moving brand-new inbound traffic to a healthy zone. Nevertheless, it’s likewise possible for several fragment copies throughout both active zones to be not available in cases of 2 node failures or one zone plus one node failure (typically described as double faults), which positions a threat to schedule. To fix this difficulty, the system utilizes a fail-open system to serve traffic off the 3rd zone while it might still remain in a standby mode to make sure the system stays extremely readily available. The following diagram shows this architecture.

An impaired network gadget affecting inter-zone interaction can trigger compose demands to substantially decrease, owing to the concurrent nature of duplication. In such an occasion, the system manages a compose failover to separate the impaired zone, cutting off all ingress and egress traffic. Although with compose failovers the healing is instant, it leads to all nodes in addition to its fragments being taken offline. Nevertheless, after the affected zone is revived after network healing, fragment healing need to still have the ability to utilize the same information from its regional disk, preventing complete sector copy. Since the compose failover lead to the fragment copy to be not available, we work out compose failovers with severe care, neither too often nor throughout short-term failures.
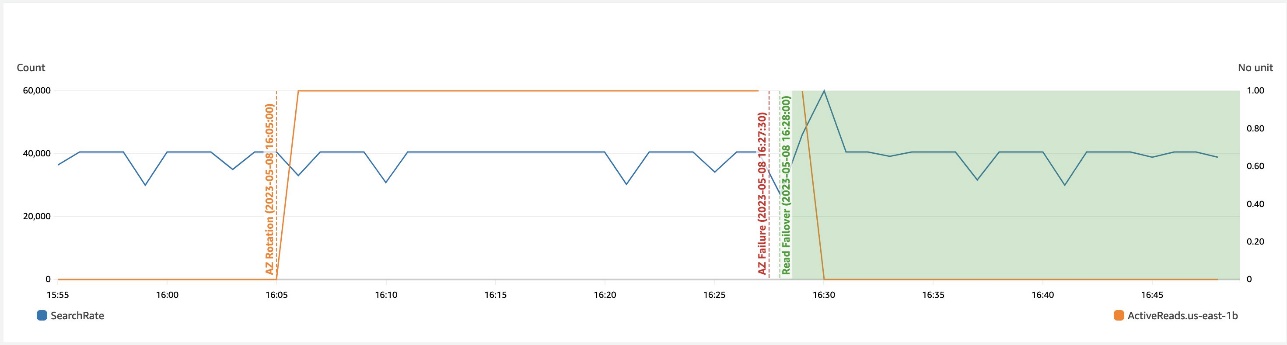
The following chart illustrates that throughout a zonal failure, automated read failover avoids any effect to schedule.
The following illustrates that throughout a networking downturn in a zone, compose failover assists recuperate schedule.

To make sure that the zonal failover system is foreseeable (able to flawlessly move traffic throughout a real failure occasion), we routinely work out failovers and keep turning active and standby zones even throughout stable state. This not just confirms all network courses, guaranteeing we do not strike surprises like clock alters, stagnant qualifications, or networking concerns throughout failover, however it likewise keeps slowly moving caches to prevent cold starts on failovers, guaranteeing we provide constant efficiency at all times.
Improving the resiliency of the service
OpenSearch Service utilizes numerous concepts and finest practices to increase dependability, like automated detection and faster healing from failure, throttling excess demands, stop working quick techniques, restricting line sizes, rapidly adjusting to satisfy work needs, carrying out loosely combined dependences, continually checking for failures, and more. We go over a few of these techniques in this area.
Automatic failure detection and healing
All faults get kept track of at a minutely granularity, throughout several sub-minutely metrics information points. When found, the system immediately activates a healing action on the affected node. Although many classes of failures talked about up until now in this post describe binary failures where the failure is conclusive, there is another sort of failure: non-binary failures, described gray failures, whose symptoms are subtle and generally defy fast detection. Sluggish disk I/O is one example, which triggers efficiency to be negatively affected. The tracking system discovers abnormalities in I/O wait times, latencies, and throughput, to spot and change a node with sluggish I/O. Faster and efficient detection and fast healing is our best option for a variety of facilities failures beyond our control.
Reliable work management in a vibrant environment
We have actually studied work patterns that trigger the system either to be strained with a lot of demands, maxing out CPU/memory, or a couple of rogue questions that can that either assign substantial pieces of memory or runaway questions that can tire several cores, either breaking down the latencies of other important demands or triggering several nodes to stop working due to the system’s resources running low. A few of the enhancements in this instructions are being done as a part of search backpressure efforts, beginning with tracking the demand footprint at numerous checkpoints that avoids accommodating more demands and cancels the ones currently running if they breach the resource limitations for a continual period. To supplement backpressure in traffic shaping, we utilize admission control, which offers abilities to decline a demand at the entry indicate prevent doing non-productive work (demands either time out or get cancelled) when the system is currently run high up on CPU and memory. The majority of the work management systems have configurable knobs. Nobody size fits all work, for that reason we utilize Auto-Tune to manage them more granularly.
The cluster supervisor carries out important coordination jobs like metadata management and cluster development, and manages a couple of background operations like picture and fragment positioning. We included a job throttler to manage the rate of vibrant mapping updates, picture jobs, and so on to avoid frustrating it and to let important operations run deterministically all the time. However what takes place when there is no cluster supervisor in the cluster? The next area covers how we fixed this.
Decoupling important dependences
In case of cluster supervisor failure, searches continue as normal, however all compose demands begin to stop working. We concluded that permitting composes in this state must still be safe as long as it does not require to upgrade the cluster metadata. This modification even more enhances the compose schedule without jeopardizing information consistency. Other service dependences were examined to make sure downstream dependences can scale as the cluster grows.
Failure mode screening
Although it’s tough to simulate all sort of failures, we count on AWS Fault Injection Simulator (AWS FIS) to inject typical faults in the system like node failures, disk problems, or network problems. Checking with AWS FIS routinely in our pipelines assists us enhance our detection, tracking, and healing times.
Adding to open source
OpenSearch is an open-source, community-driven software application. The majority of the modifications consisting of the high schedule style to support active and standby zones have actually been added to open source; in truth, we follow an open-source very first advancement design. The basic primitive that makes it possible for zonal traffic shift and failover is based upon a weighted traffic routing policy (active zones are designated weights as 1 and standby zones are designated weights as 0). Compose failovers utilize the zonal decommission action, which leaves all traffic from a provided zone. Resiliency enhancements for search backpressure and cluster supervisor job throttling are a few of the continuous efforts. If you’re thrilled to add to OpenSearch, open a GitHub concern and let us understand your ideas.
Summary
Efforts to enhance dependability is a nonstop cycle as we continue to find out and enhance. With the Multi-AZ with Standby function, OpenSearch Service has actually incorporated finest practices for cluster setup, enhanced work management, and accomplished 4 nines of schedule and constant efficiency. OpenSearch Service likewise raised the bar by continually confirming schedule with zonal traffic rotations and automated tests through AWS FIS.
We are thrilled to continue our efforts into enhancing the dependability and fault tolerance even further and to see what brand-new and existing services home builders can develop utilizing OpenSearch Service. We hope this results in a much deeper understanding of the best level of schedule based upon the requirements of your service and how this offering accomplishes the schedule shanty town. We would like to speak with you, particularly about your success stories accomplishing high levels of schedule on AWS. If you have other concerns, please leave a remark.
About the authors
 Bukhtawar Khan is a Principal Engineer dealing with Amazon OpenSearch Service. He has an interest in constructing dispersed and self-governing systems. He is a maintainer and an active factor to OpenSearch.
Bukhtawar Khan is a Principal Engineer dealing with Amazon OpenSearch Service. He has an interest in constructing dispersed and self-governing systems. He is a maintainer and an active factor to OpenSearch.
 Gaurav Bafna is a Senior Software application Engineer dealing with OpenSearch at Amazon Web Solutions. He is amazed about fixing issues in dispersed systems. He is a maintainer and an active factor to OpenSearch.
Gaurav Bafna is a Senior Software application Engineer dealing with OpenSearch at Amazon Web Solutions. He is amazed about fixing issues in dispersed systems. He is a maintainer and an active factor to OpenSearch.
 Murali Krishna is a Senior Principal Engineer at AWS OpenSearch Service. He has actually developed AWS OpenSearch Service and AWS CloudSearch. His locations of proficiency consist of Info Retrieval, Big scale dispersed computing, low latency actual time serving systems and so on. He has large experience in developing and constructing web scale systems for crawling, processing, indexing and serving text and multimedia material. Prior to Amazon, he became part of Yahoo!, constructing crawling and indexing systems for their search items.
Murali Krishna is a Senior Principal Engineer at AWS OpenSearch Service. He has actually developed AWS OpenSearch Service and AWS CloudSearch. His locations of proficiency consist of Info Retrieval, Big scale dispersed computing, low latency actual time serving systems and so on. He has large experience in developing and constructing web scale systems for crawling, processing, indexing and serving text and multimedia material. Prior to Amazon, he became part of Yahoo!, constructing crawling and indexing systems for their search items.
 Ranjith Ramachandra is a Senior Engineering Supervisor dealing with Amazon OpenSearch Service. He is enthusiastic about extremely scalable dispersed systems, high efficiency and resistant systems.
Ranjith Ramachandra is a Senior Engineering Supervisor dealing with Amazon OpenSearch Service. He is enthusiastic about extremely scalable dispersed systems, high efficiency and resistant systems.
 Rohin Bhargava is a Sr. Item Supervisor with the Amazon OpenSearch Service group. His enthusiasm at AWS is to assist consumers discover the right mix of AWS services to attain success for their service objectives.
Rohin Bhargava is a Sr. Item Supervisor with the Amazon OpenSearch Service group. His enthusiasm at AWS is to assist consumers discover the right mix of AWS services to attain success for their service objectives.