Figure 1: In real-world applications, we believe there exist a human-machine loop where people and makers are equally enhancing each other. We call it Synthetic Increased Intelligence.
How do we develop and examine an AI system for real-world applications? In a lot of AI research study, the assessment of AI approaches includes a training-validation-testing procedure. The experiments generally stop when the designs have great screening efficiency on the reported datasets since real-world information circulation is presumed to be designed by the recognition and screening information. Nevertheless, real-world applications are generally more complex than a single training-validation-testing procedure. The greatest distinction is the ever-changing information. For instance, wildlife datasets alter in class structure all the time since of animal intrusion, re-introduction, re-colonization, and seasonal animal motions. A design trained, verified, and evaluated on existing datasets can quickly be broken when freshly gathered information consist of unique types. Thankfully, we have out-of-distribution detection approaches that can assist us discover samples of unique types. Nevertheless, when we wish to broaden the acknowledgment capability (i.e., having the ability to acknowledge unique types in the future), the very best we can do is tweak the designs with brand-new ground-truthed annotations. To put it simply, we require to integrate human effort/annotations no matter how the designs carry out on previous screening sets.
When human annotations are unavoidable, real-world acknowledgment systems end up being a perpetual loop of information collection â annotation â design fine-tuning (Figure 2). As an outcome, the efficiency of one single action of design assessment does not represent the real generalization of the entire acknowledgment system since the design will be upgraded with brand-new information annotations, and a brand-new round of assessment will be performed. With this loop in mind, we believe that rather of developing a design with much better screening efficiency, concentrating on just how much human effort can be conserved is a more generalized and useful objective in real-world applications.
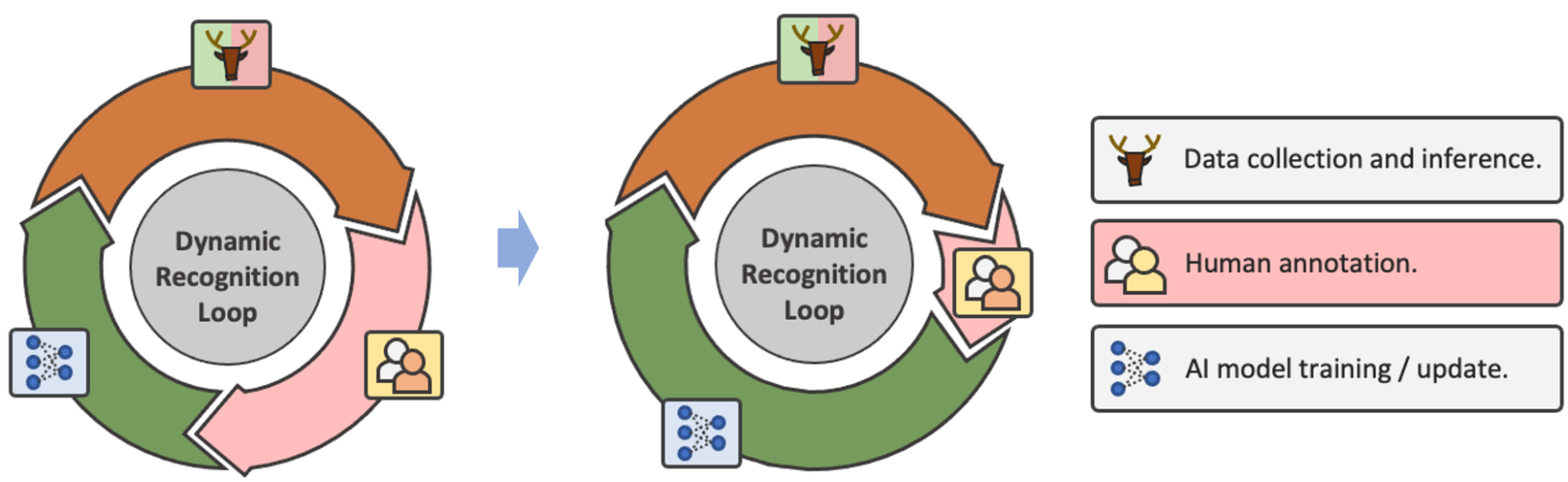
Figure 2: In the loop of information collection, annotation, and design upgrade, the objective of optimization ends up being decreasing the requirement of human annotation instead of single-step acknowledgment efficiency.
In the paper we released in 2015 in Nature-Machine Intelligence [1], we talked about the incorporation of human-in-the-loop into wildlife acknowledgment and proposed to take a look at human effort performance in design updates rather of easy screening efficiency. For presentation, we created an acknowledgment structure that was a mix of active knowing, semi-supervised knowing, and human-in-the-loop (Figure 3). We likewise included a time element into this structure to suggest that the acknowledgment designs did not stop at any single time action. Usually speaking, in the structure, at each time action, when brand-new information are gathered, an acknowledgment design actively picks which information need to be annotated based upon a forecast self-confidence metric. Low-confidence forecasts are sent out for human annotation, and high-confidence forecasts are relied on for downstream jobs or pseudo-labels for design updates.
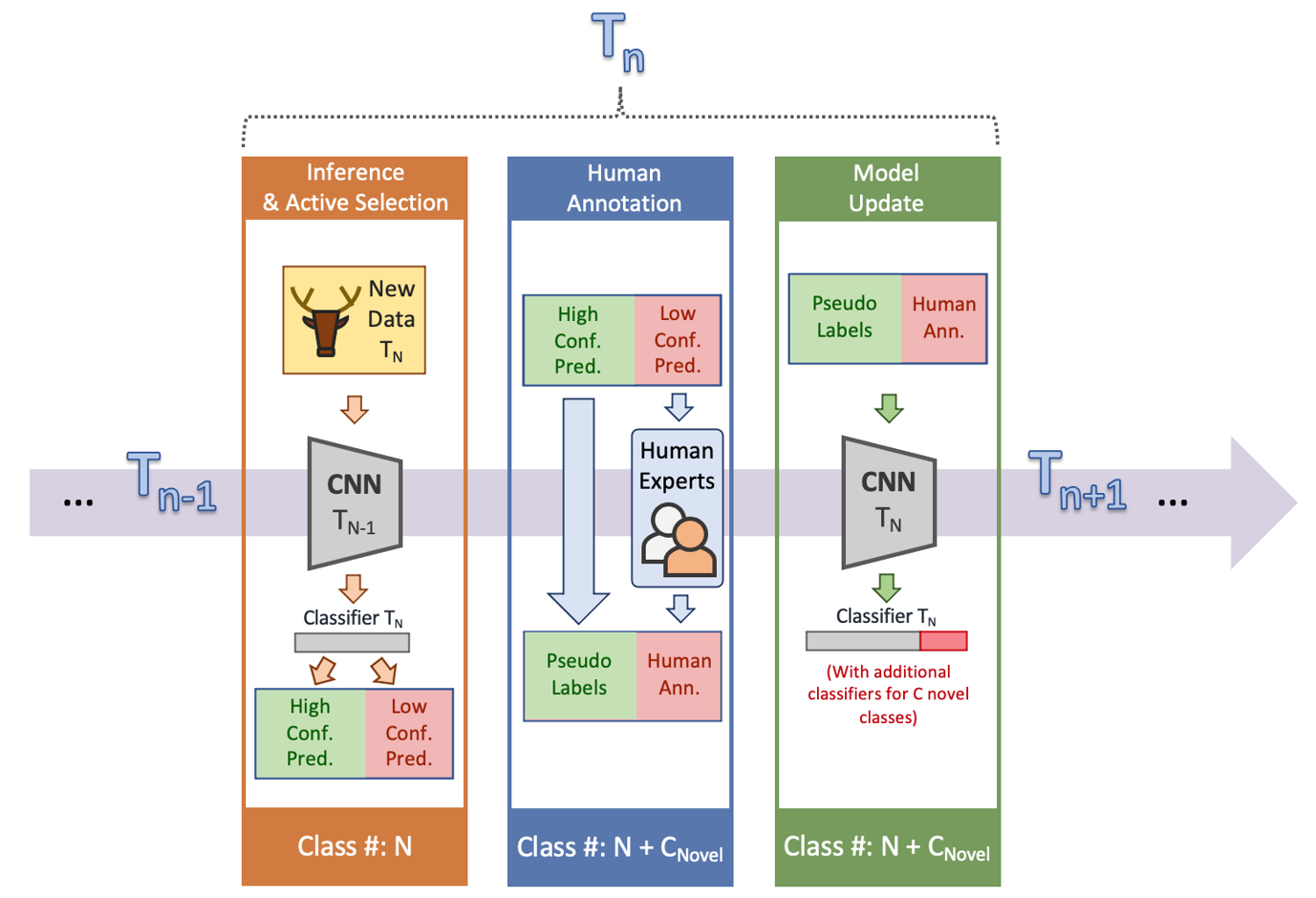
Figure 3: Here, we provide an iterative acknowledgment structure that can both make the most of the energy of modern-day image acknowledgment approaches and reduce the reliance on manual annotations for design upgrading.
In regards to human annotation performance for design updates, we divided the assessment into 1) the portion of high-confidence forecasts on recognition (i.e., conserved human effort for annotation); 2) the precision of high-confidence forecasts (i.e., dependability); and 3) the portion of unique classifications that are found as low-confidence forecasts (i.e., level of sensitivity to novelty). With these 3 metrics, the optimization of the structure ends up being decreasing human efforts (i.e., to make the most of high-confidence portion) and taking full advantage of design upgrade efficiency and high-confidence precision.
We reported a two-step experiment on a massive wildlife video camera trap dataset gathered from Mozambique National forest for presentation functions. The initial step was an initialization action to initialize a design with only part of the dataset. In the 2nd action, a brand-new set of information with recognized and unique classes was used to the initialized design. Following the structure, the design made forecasts on the brand-new dataset with self-confidence, where high-confidence forecasts were relied on as pseudo-labels, and low-confidence forecasts were supplied with human annotations. Then, the design was upgraded with both pseudo-labels and annotations and prepared for the future time actions. As an outcome, the portion of high-confidence forecasts on 2nd action recognition was 72.2%, the precision of high-confidence forecasts was 90.2%, and the portion of unique classes found as low-confidence was 82.6%. To put it simply, our structure conserved 72% of human effort on annotating all the 2nd action information. As long as the design was positive, 90% of the forecasts were appropriate. In addition, 82% of unique samples were effectively found. Information of the structure and experiments can be discovered in the initial paper.
By taking a more detailed take a look at Figure 3, besides the information collection – human annotation – design upgrade loop, there is another human-machine loop concealed in the structure (Figure 1). This is a loop where both people and makers are continuously enhancing each other through design updates and human intervention. For instance, when AI designs can not acknowledge unique classes, human intervention can supply info to broaden the design’s acknowledgment capability. On the other hand, when AI designs get increasingly more generalized, the requirement for human effort gets less. To put it simply, using human effort gets more effective.
In addition, the confidence-based human-in-the-loop structure we proposed is not restricted to unique class detection however can likewise aid with problems like long-tailed circulation and multi-domain inconsistencies. As long as AI designs feel less positive, human intervention can be found in to assist enhance the design. Likewise, human effort is conserved as long as AI designs feel great, and in some cases human mistakes can even be fixed (Figure 4). In this case, the relationship in between people and makers ends up being synergistic. Hence, the objective of AI advancement modifications from changing human intelligence to equally enhancing both human and device intelligence. We call this kind of AI: Artificial Increased Intelligence (A 2 I)
Since we began dealing with expert system, we have been asking ourselves, what do we produce AI for? In the beginning, our companied believe that, preferably, AI needs to completely change human effort in easy and tiresome jobs such as massive image acknowledgment and automobile driving. Hence, we have actually been pressing our designs to a concept called “human-level efficiency” for a long period of time. Nevertheless, this objective of changing human effort is fundamentally developing opposition or an equally special relationship in between people and makers. In real-world applications, the efficiency of AI approaches is simply restricted by a lot of impacting aspects like long-tailed circulation, multi-domain inconsistencies, label sound, weak guidance, out-of-distribution detection, and so on. The majority of these issues can be in some way alleviated with correct human intervention. The structure we proposed is simply one example of how these different issues can be summed up into high- versus low-confidence forecast issues and how human effort can be presented into the entire AI system. We believe it is not cheating or giving up to difficult issues. It is a more human-centric method of AI advancement, where the focus is on just how much human effort is conserved instead of the number of screening images a design can acknowledge. Prior to the awareness of Artificial General Intelligence (AGI), we believe it is beneficial to even more check out the instructions of machine-human interactions and A 2 I such that AI can begin making more effects in numerous useful fields.

Figure 4: Examples of high-confidence forecasts that did not match the initial annotations. Lots of high-confidence forecasts that were flagged as inaccurate based upon recognition labels (supplied by trainees and resident researchers) remained in truth appropriate upon closer assessment by wildlife professionals.
Recognitions: We thank all co-authors of the paper “Iterative Human and Automated Recognition of Wildlife Images” for their contributions and conversations in preparing this blog site. The views and viewpoints revealed in this blog site are entirely of the authors of this paper.
This post is based upon the following paper which is released at Nature – Device Intelligence:
[1] Miao, Zhongqi, Ziwei Liu, Kaitlyn M. Gaynor, Meredith S. Palmer, Stella X. Yu, and Wayne M. Getz. “Iterative human and automatic recognition of wildlife images.” Nature Device Intelligence 3, no. 10 (2021 ): 885-895.( Link to Pre-print)